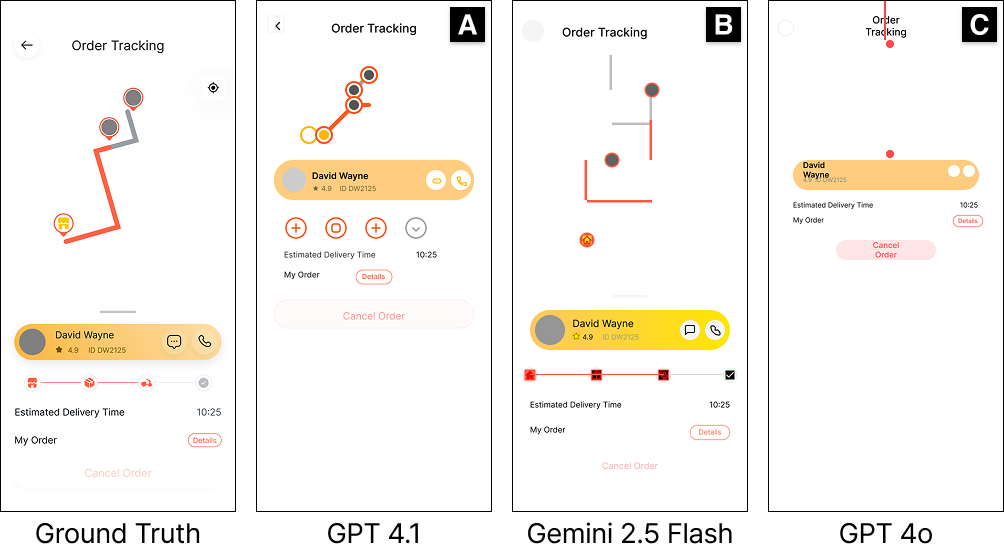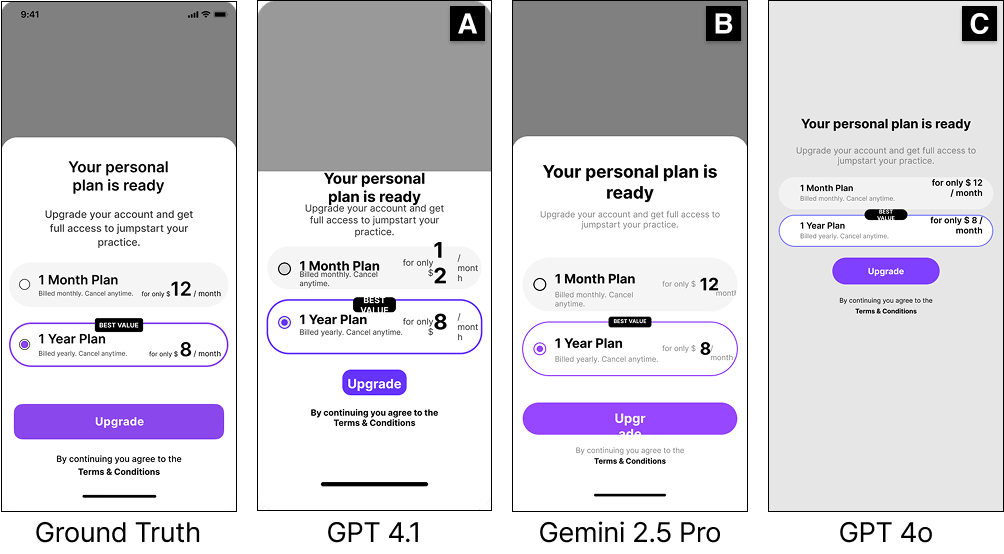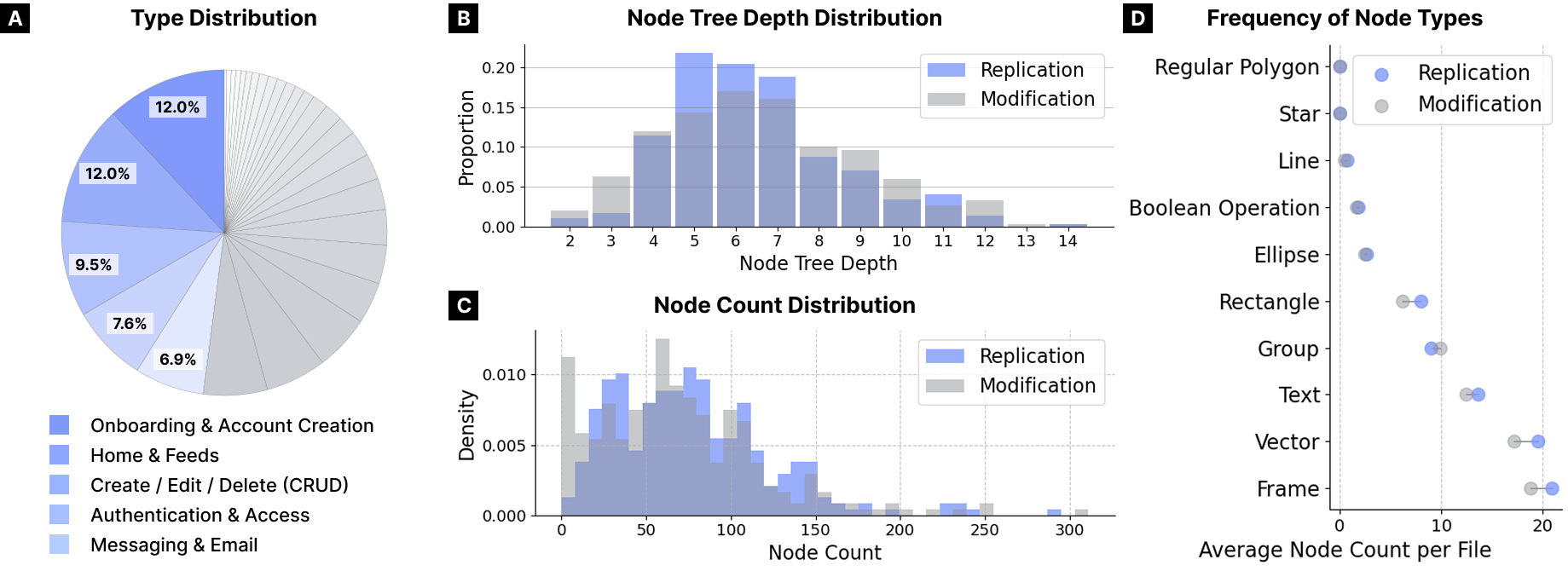
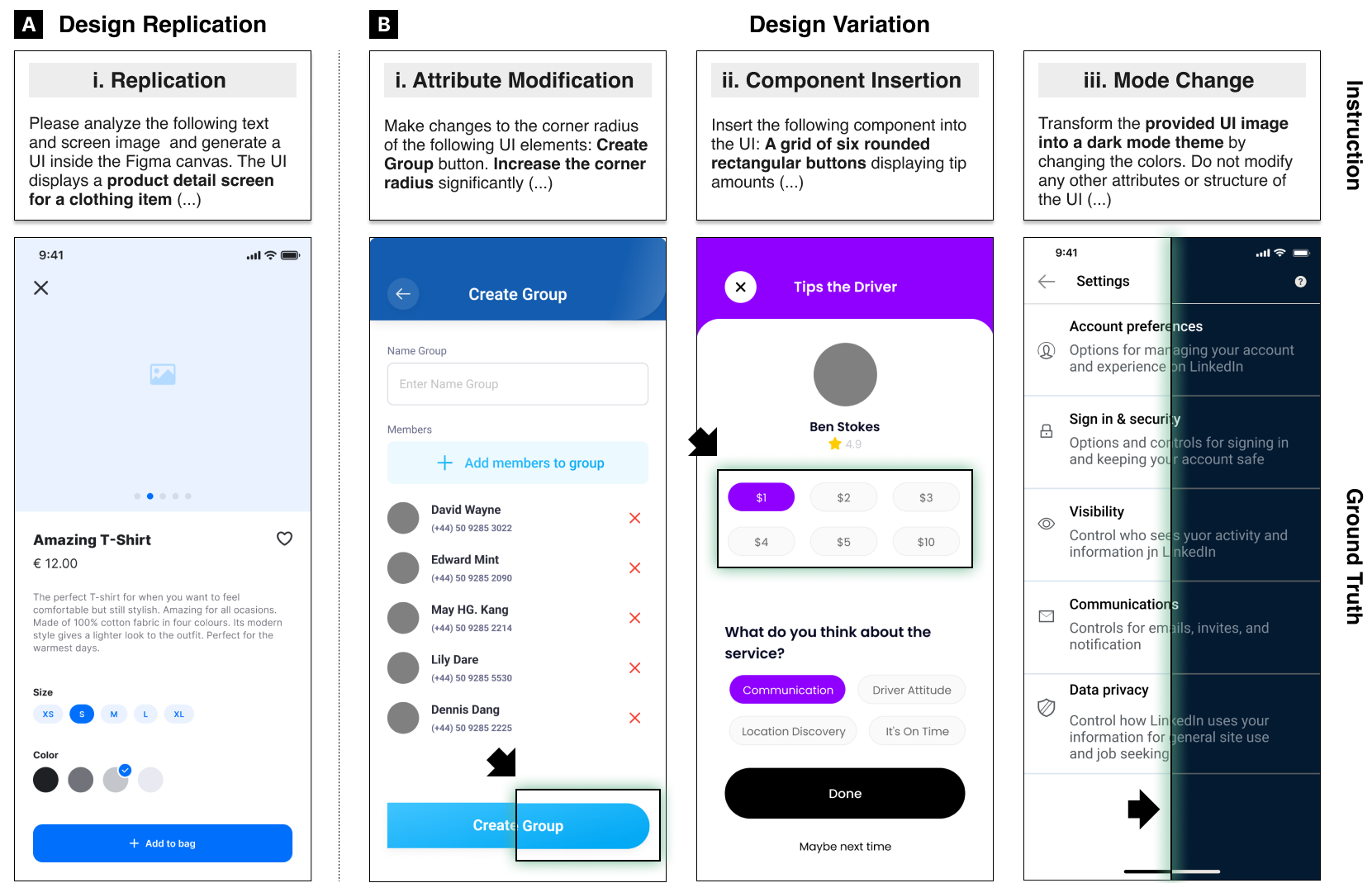
Key Results
Our evaluation of five state-of-the-art VLMs reveals important insights about tool-based UI design capabilities.
Highlights
- Replication Task: Gemini-2.5-Pro achieved highest SSIM (0.774) and Saliency (0.630)
- Modification Task: GPT-4.1 led across all metrics (SSIM: 0.890, Saliency: 0.861)
Replication Strategy
High-scoring models invoke a wider range of tools across more turns, often reusing components strategically (e.g., copy and propagate) rather than recreating them sequentially.
Modification Precision
Small inaccuracies in edits propagate unevenly across metrics, making precision more important than diversity. Models with higher tool precision achieve better modification scores.
Human Alignment
Our evaluation metrics (saliency, BLIP, component similarity) strongly correlate with human judgments of design quality, confirming that they capture expert preferences, achieving 75% prediction accuracy for human pairwise judgments.